Einleitung
Die erweiterte Markup-Sprache XML (eXtensible Markup Language) ist ein Dokumentenverarbeitungsstandard, der vom World-Wide-Web-Konsortium (W3C) vorgeschlagen wurde - demselben Gremium, das auch für die Überwachung des HTML-Standards verantwortlich ist. Obwohl die genauen Spezifikationen noch nicht fertiggestellt sind, erwarten viele, dass XML und die mit XML verwandten Technologien HTML bei dynamisch erzeugtem Inhalt, einschließlich nicht statischer Webseiten, als die Markup-Sprache der Wahl ersetzen wird. Schon jetzt ist XML ein integraler Bestandteil der IT-Welt und nicht mehr aus ihr wegzudenken. Vor allem im Backend-Bereich eröffnet es neue Perspektiven für den plattformübergreifenden Datentransfer. Doch auch für Homepage-Bastler wird XML auf die Dauer nachhaltige Änderungen mit sich bringen. Mehrere Hersteller von Browsern und Textprozessoren integrieren XML bereits in ihre Produkte.
Was ist also XML?
XML ist, ebenso wie sein Verwandter HTML, eine Markierungssprache. Beide sind
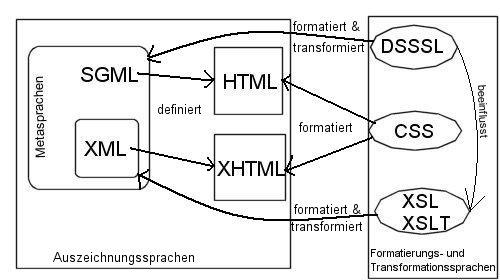
abgeleitet von der "Standard Generalized Markup Language", kurz SGML.
Zu erkennen ist dies auch an ihrer ähnlichen Syntax. Doch während
XML eine Untermenge von SGML darstellt, ist HTML lediglich eine Anwendung jener.
XML ist eine Teilmenge von SGML. Für beide gilt, dass DSSSL-Stylesheets auf sie anwendbar sind. XML-Daten lassen sich allerdings auch in Verbindung mit CSS, Level 2, anzeigen. HTML schließlich ist eine SGML-Anwendung, eine Dokumenttyp-Definition. Mit ein paar Veränderungen hat das World Wide Web Consortium (W3C) Anfang 2000 HTML als eine Anwendung von XML umgesetzt. Das heißt, das Konsortium hat HTML in XML (statt SGML) neu definiert. Nur für HTML waren ursprünglich die Cascading Style Sheets gedacht, die sich jetzt auch auf XHTML anwenden lassen.
Der Ansatz, den XML verfolgt, ist verblüffend einfach: Im Gegensatz zu seinem Artverwandten HTML stellt es lediglich einen Weg dar, Daten zu strukturieren und zu beschreiben, ohne ihnen jedoch eine Bedeutung zukommen zu lassen. Somit sind die reinen Informationen eines XML-Dokuments zunächst nutzlos, da nicht klar ist, wie sie zu deuten sind. Die wahre Stärke von XML liegt in den zahlreichen Technologien und Sprachen, die die Daten erst interpretieren und ihnen somit einen Sinn einhauchen. Ohne diese ist die Funktionalität von XML stark eingeschränkt.
Für HTML hingegen gilt dies nicht: Jede einzelne Markierung hat hier eine bestimmte Bedeutung. Der Browser "weiß", wie er die verschiedenen Tags darstellen muß. Beispielsweise wird er einen Textblock, der in <i>-Tags gekapselt ist, kursiv darstellen. Um eine HTML-Datei anzuzeigen, werden somit keine weiteren Sprachen benötigt, es bedarf lediglich eines Agenten, der HTML-Dokumente darstellen kann.
Der große Nachteil dieser Art der Datenstrukturierung liegt auf der Hand: HTML trennt nicht zwischen den reinen Daten und den Informationen, die gebraucht werden, um jene entsprechend darzustellen. Es ist damit eine sehr unsaubere Art der Organisation von Daten und erschwert das Herausfiltern von Informationen aus dem zusammengeworfenen Datenbrei. Auch eigene Tags können nicht definiert werden, da der Browser in diesem Fall nicht wissen würde, wie er diese zu deuten hat.
Ein weiterer großer Unterschied zwischen HTML und XML besteht in der Genauigkeit der beiden Sprachen: Bei HTML ist es egal, ob die Tags groß oder klein geschrieben werden, dies bleibt dem Autor des Dokuments selbst überlassen. Auch stört es die meisten Browser nicht, wenn Tags, wie z.B. <td> oder <tr>, nicht durch deren End-Tags geschlossen sind. In solchen Fällen zeigt sich der Agent nachsichtig und setzt die fehlenden Tags ein. Dieses komfortable Verhalten ist jedoch sehr fehleranfällig.
XML ist in dieser Beziehung strikter: Es unterscheidet zwischen Groß- und Kleinschreibung, und der jeweilige XML-Parser gibt sofort eine Fehlermeldung aus, falls ein Tag nicht durch ein entsprechendes Abschluß-Tag geschlossen wird. Dies kommt letztendlich dem Programmierer zugute, da Fehler bereits von Anfang an unterbunden werden.
Die Mankos von HTML, vor allem seine mangelnde Flexibilität und die Vermischung von Information und Darstellung, scheinen bei XML ausgemerzt zu sein. Dies heißt jedoch nicht, dass XML das alternde HTML ersetzen wird. HTML wird auch weiterhin bestehen bleiben, und zwar als eines jener "Werkzeuge", derer sich XML bedient. Wie bereits angesprochen, enthält ein XML-Dokument reine Daten, ohne Informationen, wie diese angezeigt werden. Daher wird mit Hilfe einer Parser-Sprache wie XSL die reinen Informationen in ein HTML-Dokument übersetzt. Dieses kann der Browser dann wiederum problemlos darstellen. Dennoch läßt sich mit XML sehr viel mehr bewerkstelligen als nur die reine Erzeugung von HTML-Code.
Eine Übersicht über ein XML-Dokument:
Es gibt im allgemeinen drei Dateien, die von einer XML-konformen Anwendung bearbeitet werden, um den XML-Inhalt darzustellen:
# Das XML-Dokument
Diese Datei enthält die Dokumentdaten, üblicherweise gekennzeichnet durch aussagekräftige XML-Elemente, von denen einige auch zusätzlich Attribute enthalten können.
# Ein Stylesheet
Das Stylesheet diktiert, wie die Dokumentelemente formatiert werden sollen, wenn sie dargestellt werden. Ob sie mit einem Textverarbeitungsprogramm oder mit einem Browser angezeigt werden, ist dabei gleichgültig. Zu beachten ist, dass je nach Umgebung verschiedene Stylesheets auf das gleiche Dokument angewendet werden können und somit dessen Erscheinungsbild verändern, ohne die zugrundeliegenden Daten zu beeinflussen. Die Trennung zwischen Inhalt und Formatierung ist ein wichtiges Unterscheidungsmerkmal in XML.
# Dokumenttypdefinition (DTD)
Diese Datei bestimmt die Regeln, wie die XML-Elemente, Attribute und andere Daten definiert und mit einem logischen Bezug zueinander in einem XML-Dokument dargestellt werden können.
Dokumente:
Bestandteile eines Dokumentes:
Ein Dokument ist aufgebaut aus :
# den Inhalt (Text, Bilder usw.)
# Information zur Darstellung (Formatierung, Layout, Schriftart usw.)
# Struktur (Aufteilung in Kapitel, Abschnitte usw.)
Das SGML-Konzept: Generic Markup:
Die wesentliche Idee von SGML, nämlich das Konzept des generic coding ist
es, den Informationsgehalt eines Dokuments von seiner äußeren Form
zu trennen. Generic Markup (Artmäßige Auszeichnung) in XML und SGML
erlaubt, im Gegensatz zu HTML, Elementnamen selbst zu definieren. Man kann sie
nach ihrer Bedeutung für die Struktur benennen. Im Prinzip kann man sie
benennen wie man will. In HTML dagegen stehen die Elementtypen (=-namen) - auch
in ihrer Anzahl - fest.
Bsp. Vergleich von XML und HTML:
In HTML:
<h1>Notebook P200</h1>
<br> Giga Computer Shop
<br> 2999,00 EUR
In XML:
<produkt>
<modell>Notebook P200</modell>
<haendler>Giga Computer Shop</haendler>
<preis>2999,00 EUR</preis>
</produkt>
Bei den XML-Daten handelt es sich um intelligente Daten. HTML teilt mit, wie
die Daten aussehen sollen, während XML mitteilt, was sie bedeuten.
Bei der Verwendung von XML weiß der Browser, dass es um ein Produkt geht,
und er kennt das Modell, den Händler und den Preis. Es wäre zum Beispiel
möglich aus einer Gruppe von solchen Angeboten das billigste Produkt herauszufinden
und anzuzeigen.
Im Gegensatz zu HTML erzeugt man bei XML eigene Tags, sodass diese genau die
Eigenschaft beschreiben, die wichtig sind.
Aber bei den XML-Daten handelt es sich nicht nur um intelligente Daten, sondern
auch um ein intelligentes Dokument. Das bedeutet, dass beim Anzeigen der Informationen
beispielsweise für die Modellbezeichnung eine andere Schriftart verwendet
werden kann als für den Händlernamen oder dass der niedrigste Preis
grün hervorgehoben werden kann. Anders als bei HTML, wo Text einfach nur
Text ist, der auf einheitliche Weise dargestellt wird, ist Text bei XML so intelligent,
dass er die eigene Darstellung steuern kann.
Die historische Entwicklung bis zur XML:
