Seminar Softwareentwicklung (Programmierstil), WS2002/2003
Johannes Kepler Universität Linz, System Software Group
Betreuer: Prof. Hanspeter Mössenböck
Autor: Clemens Holzmann
E-Mail: holzmann@soft.uni-linz.ac.at
Diese Seminararbeit behandelt Software-Metriken (im Folgenden einfach als Metriken bezeichnet), die es ermöglichen, Eigenschaften von Softwareprodukten oder -prozessen zu quantifizieren, um sie beurteilen und vergleichen zu können. Im ersten Teil dieser Arbeit wird beschrieben, was man überhaupt unter Metriken versteht und wie man sie einsetzen kann. In diesem Zusammenhang wird auch auf Vorteile beim Einsatz von Metriken sowie den damit verbundenen Problemen eingegangen. Darüber hinaus werden Kriterien angeführt, die für eine Metrik erfüllt sein müssen. Im zweiten Teil wird dann eine mögliche Klassifikation aller Metriken vorgenommen, um anschließend einige bekannte Vertreter der verschiedenen Kategorien ausführlicher zu beschreiben.
In jeder Disziplin, die ingenieurmäßig vorgeht, spielen die Begriffe Zählen und Messen eine wichtige Rolle. So gibt es z.B. vom Physiker Clerk Maxwell und Buchautor und Projektleiter Tom De Marco folgende Zitate: [Lich02]
| "To measure is to know" [C. Maxwell] |
| "You cannot control what you cannot measure” [Tom De Marco] |
Ebenso wollen auch die Softwaretechniker schon seit langem die softwaretechnische Komplexität, also die "Schwierigkeit" von Algorithmen und Programmen, messen, wobei das Ziel ist, diese durch nur eine (oder einige wenige) Zahlen auszudrücken, um sie charakterisieren und vergleichen zu können. [Rech86]
Bei der Softwaremessung geht es nun darum, für einige Merkmale eines Softwareproduktes oder -prozesses einen numerischen Wert abzuleiten. Und durch den Vergleich dieser Werte untereinander sowie mit organisationsweit geltenden Standards ist es möglich, Schlussfolgerungen über die Qualität der Software bzw. des Softwareprozesses zu ziehen und bei Bedarf geeignete Maßnahmen einzuleiten. [Somm01]
Und da die Software immer häufiger die Verantwortung für die Beherrschung komplexer Systeme übernehmen muss, wird man in Zukunft auf ein Qualitätsmanagement, das den gesamten Software-Lebenszyklus umspannt, nicht mehr verzichten können.
Die Bestandteile eines solchen Qualitätsmanagements sind beispielsweise im bekannten "Capability Maturity Level" (CMM) beschrieben, in dem die notwendigen Verfahren erläutert werden, die zu einem reifen Entwicklungsprozess führen. CMM unterscheidet fünf Reifegrade, auf denen sich ein bestimmter Softwareentwicklungs-Prozess befinden kann. Ab der vierten Stufe - man spricht dann von einem gesteuerten Prozess - werden Software-Messungen als zentrales Steuerorgan eingesetzt, wodurch das Management eine objektive Basis hat, um Entscheidungen treffen zu können. [Hind99]
Aber wie kann man nun die Qualität von Software messen? Hierfür werden sg. Software-Metriken verwendet, die unterschiedliche Eigenschaften von Softwareprodukten oder -prozessen quantifizieren.
Ganz allgemein ist eine Metrik eine zahlenmäßige Abbildung einer Eigenschaft. Analog dazu ist im IEEE- Standard 1061 der Begriff Softwarequalitätsmetrik folgendermaßen definiert:
| "Eine Softwarequalitätsmetrik ist eine Funktion, die eine Software-Einheit in einen Zahlenwert abbildet. Dieser berechnete Wert ist interpretierbar als der Erfüllungsgrad einer Qualitätseigenschaft der Software-Einheit." |
Unter den Qualitätseigenschaften von Software versteht man dabei in erster Linie Fehlerfreiheit, Zuverlässigkeit, Effizienz, Benutzungsfreundlichkeit, Wartbarkeit etc. Aber auch Termintreue und Reproduzierbarkeit zählen zu den Qualitätseigenschaften. [Hind99]
Eine weitere Definition wäre die nach Ian Sommerville, der unter einer Softwaremetrik jede Art von Messung versteht, welche sich auf ein Softwaresystem, einen Softwareprozess oder die dazugehörige Dokumentation bezieht. [Somm02]
Nachdem nun bekannt ist, was Metriken überhaupt sind, wird im Folgenden genauer auf den Nutzen von Metriken eingegangen, also welche Ziele mit deren Verwendung verfolgt werden.
Metriken sind einmal ein Ansatzpunkt für präventive Wartung. Denn wenn es gelingt, die Qualitätseigenschaften von Softwareprodukten mithilfe von Software-Metriken zu quantifizieren, könnte man bei zu negativen Ergebnissen eine präventive Überarbeitung der Software, im objektorientierten Kontext auch Refaktorisieren genannt [Fowler00], einleiten. [Hind99] Metriken dienen dabei einfach der Suche von potentiellen Problemstellen im Sourcecode, wobei die Entscheidung, ob eine Stelle einer Überarbeitung bedarf, nach wie vor dem Entwickler selbst obliegt, da es zZt. noch kein System von Metriken gibt, welches in der Lage ist, die menschliche Intuition zu ersetzen. Außerdem kann mit Hilfe von Metriken nach einer Refaktorisierung beurteilt werden, wohin die Komplexität verlagert wurde, wie viel man durch die Änderung gewonnen oder verloren hat und ob die Gesamtkomplexität vermindert wurde. [Fowler00]
Ein weiteres Ziel ist, dass die Softwareentwicklung vorhersagbarer wird: es gibt eigene Metriken für die Aufwandsabschätzung, wie z.B. die Function-Point-Metrik, welche aus den Produktanforderungen den Projektaufwand in Personenmonaten ableitet. [Hind99] Solche Metriken sind besonders für das Management interessant, u.a. um eine Aufwands-, Kosten- und Produktivitätsabschätzung vornehmen zu können.
Für die Softwareentwickler sind vor allem Sourcecode-Metriken von Bedeutung, welche die Lesbarkeit und damit den Wartungs- und Testaufwand eines Programms beurteilen, indem sie die Größe und Komplexität von Modulen messen.
Software-Metriken können auch als Ergänzung der Programmierrichtlinien verwendet werden, indem man bestimmte Grenzen für Zeilenanzahl pro Modul oder Schachtelungstiefe, Parameterzahl etc. setzt. [Hind99]
Mit Hilfe von Metriken kann man auch Schwachstellen identifizieren, indem sie diejenigen Programmteile lokalisieren, die aufgrund ihrer hohen Komplexität besonders sorgfältig getestet werden müssen. Im Zuge dessen kann außerdem beurteilt werden, ob die komplexesten Programmteile - wie es sein sollte - auch von den Entwicklern mit der größten Erfahrung geschrieben wurden. [Rech86]
Metriken eigenen sich auch dazu, Kundenanforderungen überprüfbar zu machen. Für den Auftraggeber ist besonders die Zuverlässigkeit und Wartbarkeit eines Produktes interessant, wie beispielsweise die durchschnittliche Modulkomplexität oder die Modularität. In der Anforderungsdefinition können so präzise Komplexitätsschranken vorgegeben werden, die der Auftragnehmer einfach mit Hilfe von Metriken überprüfen kann und dann auch einhalten muss. [Rech86]
Nicht zuletzt hat der Einsatz von Metriken in einem Unternehmen einen erzieherischen Effekt auf die Programmierer. Denn wer weiß, dass sein Programm routinemäßig auf bestimmte Kriterien hin überprüft wird, wird diese von vornherein zu erfüllen versuchen. [Rech86]
Trotz der eben gehörten Vorteile ist der Einsatz von Metriken in der Praxis noch relativ unüblich, was auf verschiedene Gründe zurückgeführt werden kann.
Zum einen verläuft die Einführung von Messungen zögerlich, da der Nutzen oft unklar ist. Dies liegt u.a. daran, dass in viele Firmen die angewendeten Softwareprozesse meist noch nicht genügend ausgereift sind, um von Messungen Gebrauch machen zu können.
Ein weiterer Grund ist das Fehlen von Standards für Metriken und die daher begrenzte Werkzeugunterstützung bei der Datenerfassung und - analyse. Und die meisten Firmen werden nicht bereit sein, Messungen einzuführen, solange solche Standards und Werkzeuge nicht zur Verfügung stehen. [Somm01]
Ein meiner Ansicht nach gewichtiger Grund ist aber psychologischer Natur. Programmierer wehren sich einfach dagegen, dass ihre Arbeit gemessen wird, weil sie dabei das Gefühl haben, dass nicht ihre Arbeit sondern sie selbst gemessen werden. [Wal01] Es besteht also wahrscheinlich nicht ganz zu Unrecht die Angst davor, dass es durch eine unternehmensweite Einführung von Metriken zu "gläsernen Mitarbeitern" kommen kann. [Hind99]
Software-Messung - die sich sowohl auf ein Software-Produkt als auch auf einen Software-Prozess beziehen kann - ist ein kontinuierlicher Prozess, bei dem Messgrößen definiert und Messwerte gesammelt werden. Um aber Messgrößen - wie beispielsweise die Anzahl der Codezeilen (LOC) eines Moduls - definieren zu können, muss man zuerst einmal wissen, was überhaupt gemessen werden sollte, also welche Ziele man damit verfolgt - beispielsweise die Bestimmung der Größe einer Methode - und auf welches Objekt - in diesem Beispiel die betrachtete Methode - die Messung angewendet werden sollte. [Wal01]
Anschließend werden die Messwerte interpretiert, beispielsweise um den Softwareprozess zu steuern oder um ein Software-Produkt besser zu verstehen. Hierfür sollte es aber eine eindeutige Bewertungsskala geben, die z.B. eine Differenzierung der Werte nach gut und schlecht ermöglicht. [Wal01] (So könnten weniger als 50 Codezeilen für ein Modul als gut und alles andere als schlecht beurteilt werden)
Überlegt man sich hingegen nicht, warum man eigentlich misst und wie die Ergebnisse zu interpretieren sind, wenn man also einfach alle möglichen Metriken ermittelt, kann das zu schwer interpretierbaren "Zahlenfriedhöfen" führen. Das bedeutet, dass man einen Berg von Messergebnissen hat, aber nicht wirklich weiß, wie man diese beurteilen sollte.
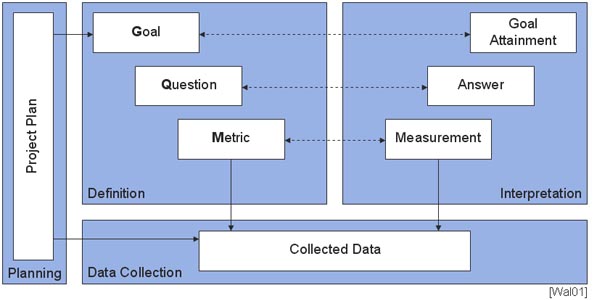
Um aber solche "Zahlenfriedhöfe" zu vermeiden, sollten Messungen immer zu einem bestimmten Zweck durchgeführt werden. Hierfür gibt es seit 1988 das sg. GQM-Muster, das im nächsten Kapitel kurz beschrieben wird. [Wal01]
Der Grundgedanke von GQM ist, dass Messungen immer mit einem bestimmten Ziel ausgeführt werden. Es werden also nicht irgendwelche Metriken ermittelt, sondern es wird nur das gemessen, was dazu beiträgt, die gesetzten Ziele zu erreichen. [Lich02]
Der GQM-Ansatz gliedert sich nach [Wal01] in vier Phasen:
In der zweiten Phase, der Definitions-Phase, wird das Messprogramm definiert, wobei der eigentliche GQM-Ansatz zum Tragen kommt.
In der darauf folgenden Phase, der Datensammlungs-Phase, werden nun die Messwerte zu den zuvor definierten Metriken gesammelt. Bei Sourcecode-Metriken können hierfür Werkzeuge wie z.B. das Java-Code-Review-Tool JStyle [JStyle] verwendet werden.
In der vierten und letzten Phase, der Interpretations-Phase, werden die gesammelten Daten schließlich bzgl. der definierten Metriken ausgewertet. Hierfür eignen sich Tabellenkalkulations- und Statistikprogramme [Hind99], die in den Werkzeugen oft schon integriert sind. Man bekommt nun aus der Messdaten-Sammlung die entspr. Messergebnisse zur jeweiligen Metrik (Measurement), welche die Antworten auf die zuvor definierten Fragen liefern (Answer). Mit diesen Antworten kann schließlich beurteilt werden, ob die Ziele erreicht wurden (Goal-Attainment).
Der Vorteil dieses Verfahrens liegt darin, dass nur das gemessen wird, was auch dazu beiträgt, die gesetzten Ziele zu erreichen. Außerdem wird die Interpretation der ausgewählten Metriken festgelegt [Lich02]; man wird also nach den Messungen nicht mit einer riesigen, kaum interpretierbaren Zahlenmenge konfrontiert.
Im Folgenden wird nun auf die Metriken selbst eingegangen, wobei zuerst einmal Gütekriterien vorstellen werden, die nach [Wal01] erfüllt sein müssen, um überhaupt von einem Software-Qualitätsmaß sprechen zu können.
Das wichtigste, aber auch das am schwierigsten nachzuweisende Kriterium ist sicherlich die Messtauglichkeit. Denn Maße, zu denen keine Aussage über deren Validität vorliegen, sind für objektive Qualitätsbewertungen unbrauchbar.
Nun noch kurz zu den für die Softwaremessung relevanten maßtheoretischen Grundlagen.
Wie zu Beginn schon erwähnt wurde, ist eine Metrik nichts anderes als eine Funktion f zwischen dem empirischen, realen Betrachtungsbereich und dem mathematisch definierten Zahlenbereich:
|
f: reale Welt |
Eine solche Abbildung setzt aber voraus, dass es auch eine Skala gibt. Das Problem dabei ist, zu entscheiden, welche Skala vorliegt, wobei man nach [Lich02] fünf Skalentypen unterscheidet, die anhand des Beispiels eines Softwaremoduls vorgestellt werden:
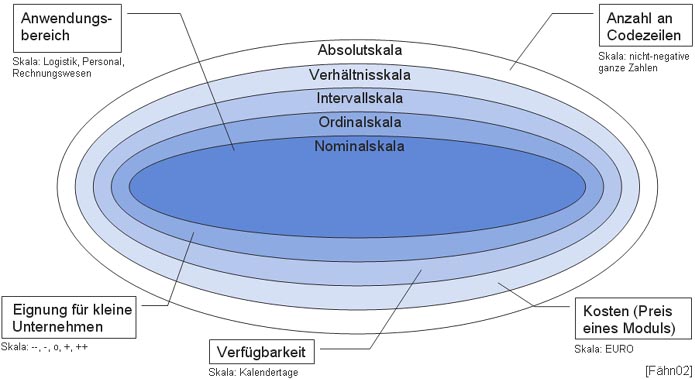
Die Kernaussage dieses Kapitels ist, dass für die zu beobachtenden Kenngrößen Skalen festzulegen sind. So kann die Anzahl der Codezeilen auf einer Absolutskala aufgetragen werden, womit auch die durchschnittliche Anzahl der Codezeilen pro Modul berechnet werden darf. Es wäre aber in obigem Beispiel nicht zulässig, z.B. die durchschnittliche Eignung aller Softwaremodule für kleine Unternehmen zu ermitteln, da es sich dabei um eine Ordinalskala handelt und Mittelwertbildung nicht erlaubt ist.
Für viele der heute bekannten Kenngrößen fehlen allerdings fundierte Aussagen über die Art der Skala, weshalb es beispielsweise zu unerlaubten Mittelwertsbildungen kommen kann und somit falsche Messinterpretationen entstehen können. [Wal01]
Es gibt eine Vielzahl von Metriken und unzählige Klassifikationsversuche. In diesem Kapitel wird anhand häufig zu findender Einteilungen versucht, einen großen Überblick über die verschiedenen Kategorien von Software-Metriken zu geben, wobei auch Mischformen möglich sind, d.h. dass sich Metriken nicht eindeutig einer dieser Kategorien zuordnen lassen.
Häufig wird zwischen Prozess- und Produktmetriken unterschieden. Bei Prozessmetriken handelt es sich um quantitative Daten des Software- Entwicklungsprozesses (es werden also Eigenschaften des Prozesses gemessen). Produktmetriken hingegen messen die Software selbst, wobei sie nichts darüber aussagen, wie das Produkt entstanden ist bzw. wieso es sich gerade in diesem Zustand befindet. [Wal01]
Der Zusammenhang zwischen Produkt- und Prozessmetriken ist in folgender Grafik anschaulich dargestellt, wobei zu den einzelnen Entwicklungsstufen Beispiele für Metriken angeführt sind:
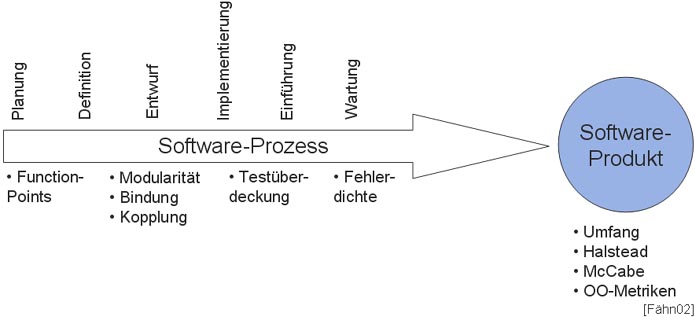
Prozessmetriken können nach [Somm01] in 3 Kategorien eingeteilt werden.
Produktmetriken befassen sich - wie bereits erwähnt - mit den Eigenschaften des Softwareproduktes selbst, wobei hier nach [Somm01] wiederum zwischen zwei Kategorien, nämlich zwischen dynamischen und statischen Produktmetriken, unterschieden werden muss.
Dynamische Produktmetriken werden durch Messungen bei der Ausführung eines Programms gesammelt und sind für die Beurteilung der Leistungsfähigkeit und Zuverlässigkeit eines Programms hilfreich. [Somm01] Zu dieser Kategorie gehört z.B. die benötigte Ausführungszeit für bestimmte Funktionen oder die Anzahl der, bei der Ausführung aufgetretenen Fehler.
Statische Produktmetriken messen die Systemdarstellung; also den Entwurf, das Programm oder die Dokumentation. [Somm01] Statische Metriken helfen beispielsweise zu beurteilen, wie komplex bzw. wartungsfreundlich ein Softwaresystem ist.
Durch die Unterschiede zwischen prozeduraler und objektorientierter Entwicklung muss bei den statischen Metriken allerdings erneut eine Unterscheidung getroffen werden, nämlich zwischen konventionellen und objektorientierten Metriken.
Zu den konventionellen Metriken werden alle nicht explizit objektorientierten, statischen Produktmetriken gezählt, welche man nach [Fähn02] und [Rech86] grob in vier Kategorien unterteilen kann:
Die zweite Kategorie stellen die objektorientierten Metriken dar. Sie wurden notwendig, um die Strukturmerkmale objektorientierter Software - Vererbung, Kapselung, Lokalisation, Information Hiding und Abstraktion, aber auch die Beziehungen der Objekte untereinander - bei der Softwaremessung berücksichtigen zu können. Es gibt bereits eine Vielzahl objektorientierter Metriken, welche sich nach [Lich02] im wesentlichen auf vier Bezugsebenen aufteilen lassen, die sich allerdings nicht gegenseitig ausschließen:
Es gibt noch eine Reihe weiterer Unterscheidungen - so z.B. zwischen extern und intern, ob also Eigenschaften gemessen werden, die für den Benutzer sichtbar sind (wie Kosten- und Aufwandsmetriken), oder ob diese nur für den Entwickler relevant sind (wie Größen- und Komplexitätsmetriken) - welche aber den Rahmen dieser Arbeit sprengen würden. Weitere Informationen dazu finden sich beispielsweise in [Bert98] und [Fähn02].
Die Function-Points-Metrik ist zwar eine weit verbreitete aber wahrscheinlich dennoch nicht so bekannte Prozess-Metrik, weshalb sie im Folgenden etwas genauer behandelt wird.
Die Function-Points-Metrik dient der Aufwandsabschätzung, und ist deshalb besonders für das Management von Interesse. Sie leitet aus den Produktanforderungen den Entwicklungsaufwand in Personenmonaten ab, der für ein angesetzte Projekt betrieben werden muss.
Folgende Grafik sollte veranschaulichen, wie man bei der Ermittlung dieser Metrik vorgeht:
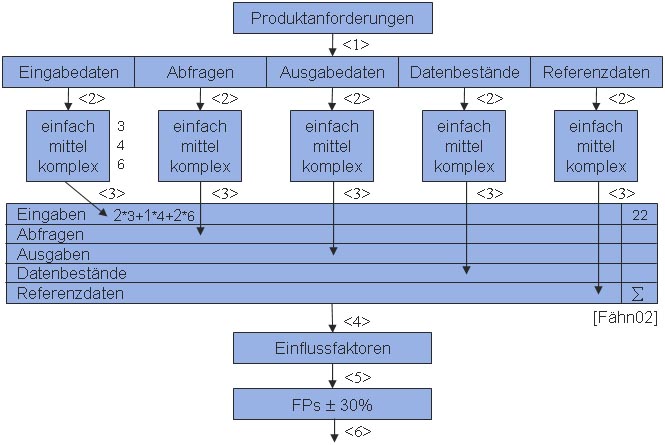
Als ersten Schritt wird jede Produktanforderung in eine von fünf Kategorien eingeteilt:
Nachdem alle Produktanforderungen in Kategorien eingeteilt wurden, werden sie in einem zweiten Schritt anhand ihrer Komplexität in einfach, mittel oder komplex eingestuft. Hierfür gibt es für jede der 5 Kategorien bereits vorgeschlagene Tabellen, anhand derer die Anforderungen entsprechend eingeteilt werden können.
Im dritten Schritt wird dann die jeweilige Anzahl an Anforderungen, die entsprechend ihrer Komplexität gewichtet werden, ins Berechnungsformular eingetragen, und die Summe berechnet. Hat man z.B. zwei einfache (welche z.B. mit 3 gewichtet werden), und zwei komplexe Eingabedaten (mit 6 gewichtet), so ergibt sich für die Kategorie Eingabedaten eine Summe von 2*3+2*6=18. Dies führt man für jede der fünf Kategorien durch und berechet schließlich eine Gesamtsumme.
Im vierten Schritt werden dann Einflussfaktoren bestimmt, die die bisher ermittelten Function-Points noch auf- oder abwerten können. Einflussfaktoren können beispielsweise eine starke Verflechtung mit anderen Systemen oder der Wunsch nach einem hohen Grad an Wiederverwendbarkeit sein.
Im fünften Schritt werden die im dritten Schritt berechneten Function-Points dann noch mit den eben ermittelten Einflussfaktoren bewertet, wobei es noch zu einer Auf- bzw. Abwertung der Function-Points um bis zu 30% kommen kann.
Im sechsten Schritt kann dann schließlich aus einer Tabelle, welche aus früheren Projekten stammt, eine Aussage über den Entwicklungsaufwand in Personenmonaten gemacht werden.
Nach Abschluss des Softwareentwicklungs-Projektes wird die Tabelle in einem siebten und letzten Schritt mit dem neuen Wertepaar Function-Points / tatsächliche Personenmonate ergänzt. Diese Methode wird also mit der Zeit immer aussagekräftiger.
Vorteil dieses Verfahrens ist die frühe Aufwandsschätzung, welche vor allem für das Management von Interesse ist.
Nachteilig bei der Function-Points-Methode ist allerdings deren beschränkte Aussagekraft bei Verwendung von Objektorientierung, da es durch die Verfügbarkeit von Klassenbibliotheken schwierig ist, die Function-Points zu zählen, da nicht feststeht, ob die durch Verwendung von Klassenbibliotheken eingebundene Funktionalität mitgezählt werden sollte oder nicht. [Micha01]
LOC ist das einfachste, älteste und nach wie vor eines der am häufigsten benutzten Komplexitätsmaße. [Rech86] LOC gehört zur Gruppe der Umfangsmetriken und misst einfach die Anzahl der der effektiven Codezeilen:
| LOC = Anzahl effektiver Codezeilen (ohne Leer- und Kommentarzeilen) |
Nachteil dieser Metrik ist aber, dass sie sowohl von der verwendeten Programmiersprache als auch vom Programmierstil abhängig ist. [Hind99] Die Aussagekraft dieses Maßes lässt sich zwar durch den Einsatz von Beautifiern verbessern, welche Programme in eine einheitliche optische Form bringen, wodurch die Anzahl der Codezeilen von Programmen verschiedener Personen innerhalb eines Unternehmen vergleichbar werden. Mehrere Anweisungen in einer Codezeile werden aber dennoch nicht berücksichtigt.
Ein aussagekräftigeres Maß ist daher NOS, da hierbei die Anzahl der Anweisungen anstelle der Codezeilen gezählt wird:
| NOS = Anzahl ausführbarer Anweisungen |
LOC und NOS können verwendet werden, um die Größe von Modulen zu beschränken oder den Preis für ein Produkt zu kalkulieren. Außerdem sind sie ein Maß für Testbarkeit und Wartbarkeit, da der Aufwand für Tests oder Einarbeitung mit der Größe eines Moduls wächst. [Hind99]
Vorteil dieser Metriken ist deren einfache Messbarkeit sowie deren starke Korrelation mit anderen Maßen wie Halstead oder McCabe, sodass man sich immer die Frage stellen muss, ob sich der Aufwand für andere Maße überhaupt lohnt! [Rech86]
Nachteil dieser einfache Metriken ist allerdings, dass die Schwierigkeit von Anweisungen und Ablaufstrukturen nicht berücksichtigt wird.
Eine andere sehr oft verwendete Umfangsmetrik ist die Halstead-Metrik [Fähn02], welche den zu erwartenden Test- und Wartungsaufwand ausdrückt. Sie beruht auf der Annahme, dass ein Programm nur aus Operanden und Operatoren besteht, wobei Operatoren Aktionen (z.B. arithmetische Operatoren wie + und *, Schlüsselwörter wie While und For sowie spezielle Symbole wie := und Klammern) und Operanden Daten (z.B. Variablen, Konstanten und Sprungmarken) kennzeichnen. [Wal01]
Halstead hat folgende drei Maße entwickelt:
| Umfang V = (N1+N2)*ld(n1+n2) |
| Schwierigkeit L = (2/n1)*(n2/N2) |
| Testaufwand E = (V/L) |
N1 und N2 bezeichnen dabei die Gesamtzahl verwendeter Operatoren und Operanden, n1 und n2 die Anzahl unterschiedlicher Operatoren und Operanden. Deren Klassifikation ist dabei sprachabhängig und wurde von Halstead nicht definiert. [Wal01]
Die Messung beschränkt sich nun darauf, die unterschiedlichen und insgesamt auftretenden Operatoren und Operanden zu zählen und die Ergebnisse in obige drei Formeln einzusetzen.
Vorteil dieses Maßes ist, dass auch komplizierte Ausdrücke berücksichtigt werden und – wie es auch sein sollte – viele verschiedene Variablen einen hohen Beitrag liefern. Darüber hinaus korreliert dieses Maß stark mit der Häufigkeit von Programmierfehlern [Rech86] und es ist bei jeder Programmiersprache anwendbar. [Fähn02]
Nachteilig ist aber, dass Ablaufstrukturen vollkommen unberücksichtigt bleiben.
Die McCabe-Metrik mißt die logische Struktur eines Programms und gehört neben der Halstead-Metrik zu den am häufigsten verwendeten Software-Maßen. McCabe vertritt den Standpunkt, dass die Programmkomplexität von der Anzahl der Hauptwege (worunter man linear unabhängige Programmpfade versteht) im dazugehörigen Kontrollflussgraphen abhängt. [Wal01]
Man geht dabei also so vor, dass zu Beginn der Kontrollflussgraph für das zu messende Programm ermittelt wird, wobei Anweisungen durch Knoten und der Kontrollfluss zwischen den Anweisungen als Kanten dargestellt wird.
Folgende Beispiele sollten dies verdeutlichen, wobei im ersten Fall einfach zwei Anweisungen sequentiell ausgeführt werden, im zweiten Beispiel sieht man eine if-Anweisung mit einem then- sowie einem else-Zweig und schließlich noch eine for-Schleife, welche ausgeführt wird, bis die Bedingung false ergibt: [Fähn02]
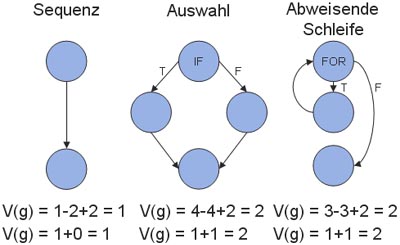
Anhand des Kontrollflussgraphen wird dann eine sg. zyklomatische Zahl V(g) errechnet, wobei V(g) nichts anderes als die Anzahl der unabhängigen Programmpfade ist.
| V(g) = e – n + 2p |
Die Anzahl der Kanten im Graphen wird dabei mit e, die Anzahl der Knoten im Graphen mit n und die Anzahl der verbundenen Komponenten n bezeichnet. Unter einer verbundenen Komponente versteht man einen einzelnen Kontrollflussgraphen; besteht ein Programm aus mehreren Methoden, so wird jede Methode als eigener Kontrollflussgraph dargestellt. [Fähn02]
Besitzt ein Programm allerdings nur einen Ein- und Ausgang, so kann dieses Maß auf sehr einfache Weise berechnet werden, was auch zu seiner großen Verbreitung geführt hat:
| V(g) = 1 + Anzahl der Binärverzweigungen |
Für die obigen drei Graphen kann V(g) auf beide Arten berechnet werden kann, da diese einfachen Graphen ohnehin nur einen Ein- und Ausgang haben.
Die McCabe-Metrik ist ein Maß für den Test- und Wartungsaufwand, wobei V(g) die minimale Anzahl an Testfällen angibt, um jeden Pfad mindestens einmal zu durchlaufen.[Rech86]
Darüber hinaus lässt sich die McCabe-Metrik auch für Strukturbeschränkungen verwenden, indem beispielsweise ein V(g) kleiner als 10 pro Methode gefordert wird. [Wal01]
Der Vorteil bei diesem Verfahren ist, dass es einfach zu messen ist; man kann den der Quellcode einfach nach den entsprechenden Schlüsselwörtern für Bedingungen - wie beispielsweise
if, case, for und while - parsen. Ausgehend von den Bedenken u.a. gegenüber McCabe und Halstead, dass zu wenige Einflussgrößen berücksichtigt werden, hat Rechenberg in [Rech86] ein Komplexitätsmaß definiert, welches sich additiv aus drei Komponenten zusammensetzt, wobei deren Addition nur aus dem Wunsch heraus geschieht, die Komplexität eines Programms letztendlich durch eine anstatt durch drei Zahlen auszudrücken:
| Gesamtkomplexität CC = SC + EC + DC |
Unter der Anweisungskomplexität SC (statement complexity) versteht man die Summe aller, nach Erfahrungswerten gewichteten ausführbaren Anweisungen. So hat z.B. eine Zuweisung das Gewicht 1, eine While-Anweisung 3, eine if-Anweisung je 1 für if, then, else und else if und ein Prozeduraufruf hat das Gewicht 1+Parameteranzahl. Des weiteren wird die Schachtelung von Schleifen und Alternativen berücksichtigt, indem mit steigender Schachtelungstiefe das jeweiligen Gewicht mit einem exponentiell ansteigenden Faktor f (f nimmt mit steigender Schachtelungstiefe typischerweise die Werte 1 - 1.5 - 2.25 - 3.38 - 5.06 - ... an) multipliziert wird, wie folgendes Beispiel einer if-Anweisung zeigt:
SC(if b then S) = 2 + f*SC(S)
Die Ausdruckskomplexität EC (expression complexity) errechnet sich aus der Summe der Ausdruckskomplexitäten der Bestandteile aller Ausdrücke, wobei jedem Bestandteil eine bestimmte Komplexität zugeteilt wird. So haben z.B. die Operatoren + und - jeweils das Gewicht 1, MOD hat das Gewicht 3 und [] hat pro Index das Gewicht 2. Auch hier wird die Schachtelung von Ausdrücken berücksichtigt, wie folgendes Beispiel zeigt:
EC(2*(i+1)) = 2 + f*EC(i+1) = 2 + f*1 = 3,5
Die Datenkomplexität DC (data complexity) bewertet alle Bezeichner nach der Entfernung zwischen Deklaration und Verwendung, wobei lokale Variablen den Wert 1, formale Parameter 2 und globale Variablen den Wert 3 haben. Die Datenkomplexität errechnet sich schließlich aus der Summe der Gewichtungen aller Bezeichner.
Der Vorteil dieses Maßes liegt in der detaillierten Betrachtung der verschiedenen Aspekte, außerdem ist es durch die frei wählbaren Gewichte flexibel.
Nachteil ist aber, dass auch dieses Maß schwer zu berechnen und nicht intuitiv verständlich ist.
Unter dem Kommentaranteil bzw. der Kommentardichte versteht man den prozentuellen Anteil aller Kommentare in Relation zum gesamten Quellcode:
| Kommentaranteil = Anzahl der Zeichen in Kommentaren geteilt durch die Gesamtzahl aller Zeichen in der Datei |
Diese Stilmetrik hat insofern Bedeutung, dass sinnvolle Kommentare zur Strukturierung des Programmtextes dessen Lesbarkeit und somit auch die Wartbarkeit erhöhen. Der Kommentaranteil ist also ein Maß für die Wartbarkeit eines Programms.
Vorteil ist, dass dieses Maß sehr einfach zu ermitteln ist.
Nachteil ist aber, dass triviale Kommentare von sinnvollen nicht unterschieden werden können. [Hind99]
Wie bereits in Kapitel 5.3 erwähnt, wurden durch die objektorientierte Programmierung neue Metriken notwendig, welche die Strukturen der Objektorientierung sowie die Beziehungen der Objekte untereinander berücksichtigen. Da es sich bei der Objektorientierung aber um ein relativ junges Gebiet handelt, sind die Erfahrungen mit diesen Metriken noch begrenzt und auch die theoretische Fundierung für diese Metriken fehlt noch. [Lich02] Ein weiteres Problem ist, dass heutige Metriken noch zu einfache Sachverhalte messen. [Fähn02]
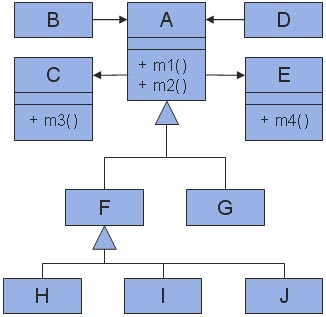
In den folgenden Unterkapiteln werden einige objektorientierten Metriken, welche der Metrik-Suite von Chidamber und Kemerer [Chidamber94] entnommen wurden, anhand des folgenden Klassendiagramms etwas genauer vorgestellt:
CBO gehört zu den Maßen auf Aggregationshierarchien und ist ein Maß für die Beziehungen der Klassen untereinander:
| CBO = Anzahl der Klassen, mit denen die betrachtete Klasse gekoppelt ist |
Zwei Klassen sind dann miteinander gekoppelt, wenn Methoden der einen Klasse Methoden oder Instanzvariablen der anderen Klasse aufrufen oder verwenden. CBO zählt dabei sowohl die Klassen, die von der gemessen Klasse benutzt werden, also auch diejenigen, die diese ihrerseits benutzt. Klassen der Vererbungshierarchie werden dabei allerdings nicht mitgezählt. [Lich02]
CBO ist damit ein Maß für die Wiederverwendbarkeit und Testbarkeit. Denn je höher die Kopplung ist, desto schwieriger ist die Klasse zu verstehen, und umso schwerer kann sie wieder verwendet und getestet werden. Darüber hinaus ist sie anfälliger für Änderungen.
In obigem Klassendiagramm ist somit beispielsweise CBO(A) = 4 (weil die Klasse A von den Klassen B und D verwendet wird und ihrerseits die Klassen C und E verwendet, wie an den gerichteten Assoziationen zu erkenne ist), CBO(B) = 1 (weil B die Klasse A verwendet) und CBO(F) = 0 (keine Benutzt-Beziehung zwischen der Klasse F und anderen Klassen).
DIT gehört zu den Maßen auf Vererbungshierarchien und misst die Tiefe des Vererbungsbaumes:
| DIT = Länge des maximalen Weges in der Vererbungshierarchie von der Wurzel bis zur betrachteten Klasse |
Der maximale Weg ist nur bei Mehrfachvererbung von Interesse, da es dabei zu unterschiedlich langen Wegen in der Vererbungshierarchie kommen kann.
DIT ist ein Maß für die Testbarkeit und Wartbarkeit, da eine Klasse umso komplexer ist, je mehr Oberklassen existieren. Außerdem können sich Änderungen in Oberklassen leicht auf die betrachtete Klasse auswirken [Lich02], was unter dem "Fragile Base Class"-Problem bekannt ist.
In obigem Klassendiagramm ist beispielsweise DIT(A) = 0 (weil A bereits die Wurzelklasse darstellt), DIT(G) = 1 (G hat eine Oberklasse, nämlich A) und DIT(H) = 2 (zwei Klassen von der Wurzelklasse A bis zur Klasse H).
NOC gehört ebenfalls zu den Maßen auf Vererbungshierarchien und misst die Anzahl der Kinder einer Klasse:
| NOC = Anzahl der unmittelbaren Spezialisierungen der betrachteten Klasse |
In obigem Klassendiagramm ist beispielsweise NOC(A) = 2 (A wird von den Klassen F und G erweitert), NOC(F) = 3 (die Klasse F wird durch die drei Klassen H, I und J erweitert) und NOC(B) = 0 (B hat keine Unterklassen).
RFC gehört zu den Maßen auf Klassenebene und ist ein Maß für die Dienste, die eine Klasse anbietet:
| RFC = Anzahl der Methoden, die potentiell ausgeführt werden können, wenn ein Objekt der betrachteten Klasse auf eine eingegangene Nachricht reagiert |
Zu dieser Menge gehören alle Methoden, die direkt aufgerufen werden können, aber auch diejenigen, die nicht in der Klasse selbst liegen, sondern durch Kopplung mit anderen Klassen erreichbar sind.
RFC hat Auswirkungen auf die Testbarkeit, da eine Klasse umso komplexer ist, umso mehr Methoden aufgerufen werden können. RFC gibt eine obere Schranke für die Anzahl der Testfälle an, die durch die möglichen Methodenaufrufen notwendig werden. [Lich02]
In obigem Klassendiagramm ist beispielsweise RFC(A) = 4 (weil bei einer Nachricht an die Klasse A sowohl die Methoden m1() und m2(), als auch die Methoden m3() der Klasse C und m4() der Klasse E ausgeführt werden können), RFC(B) = 2 (durch Kopplung mit der Klasse A können die beiden Methoden m1() und m2() ausgeführt werden), RFC(C) = 1 (nur die Methode m3() kann ausgeführt werden, da die Klasse C keinen Zugriff auf A hat) und RFC(G) = 0.
WMC gehört ebenfalls zu den Maßen auf Klassenebene und misst die Komplexität einer Klasse anhand der Komplexitäten ihrer Methoden:
| WMC = Summe der Komplexitäten aller Methoden der betrachteten Klasse |
Die Komplexitäten der Methoden kann beispielsweise durch die zyklomatische Zahl (siehe 6.4) ermittelt werden.
WMC ist ein Maß für die Verständlichkeit und Erweiterbarkeit einer Klasse. Denn je mehr Methoden eine Klasse besitzt, desto größer sind die Auswirkungen auf deren Unterklassen. Außerdem sind Klassen mit vielen Methoden häufig sehr anwendungsspezifisch und damit nur begrenzt wieder verwendbar. Darüber hinaus nimmt die Fehlerwahrscheinlichkeit mit der Anzahl der Methoden zu. [Lich02]
In obigem Klassendiagramm ist beispielsweise WMC(A) = 2, wenn die beiden Methoden der Klasse A jeweils eine Komplexität von 1 haben.
Das letzte der sechs Maße aus der Metrik-Suite von Chidamber und Kemerer ist LCOM. LCOM gehört ebenfalls zu den Maßen auf Klassenebene und ist ein Maß für den inneren Zusammenhalt (auch Kohäsion genannt) von Methoden in einer Klasse:
| LCOM = Anzahl der Paare von Methoden der betrachteten Klasse ohne gemeinsame Instanzvariablen minus Anzahl der Paare von Methoden dieser Klasse mit gemeinsamen Instanzvariablen |
Das Ergebnis von LCOM wird auf 0 gesetzt, wenn die Subtraktion einen negativen Wert ergibt.
LCOM ermöglicht es, die Kapselung einer Klasse zu überprüfen. Denn wenn viele Methoden auf disjunkten Attributmengen arbeiten, so deutet das auf eine schlechte Kapselung hin. [Lich02]
Dies sollte nun an folgendem Beispiel einer Klasse A mit drei Methoden m1, m2 und m3 veranschaulicht werden, wobei zu jeder Methode Instanzvariablen angegeben sind, auf denen sie operieren (z.B. verwendet m1 die Instanzvariablen a, b und c):
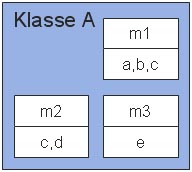
Man sieht, dass m1 und m2 die gemeinsame Instanzvariable c haben, die Schnittmenge der Instanzvariablen von m1 und m3 sowie m2 und m3 allerdings die leere Menge ist. Daraus folgt, dass LCOM(A) = 2-1 = 1.
Metriken haben vielfältige Einsatzmöglichkeiten. So werden sie beispielsweise zur Überprüfung von Qualitätseigenschaften (wie Testbarkeit, Wiederverwendbarkeit, Lesbarkeit und Wartbarkeit), zur Aufwandsabschätzung (um beispielsweise den erwarteten Aufwand für ein Projekt abzuschätzen oder den Preis für ein Produkt zu kalkulieren) als auch im Rahmen der Software-Wiederverwendung [Hind99] eingesetzt, da Qualitätseigenschaften besonderer dann von Bedeutung sind, wenn eine Anwendung von mehreren anderen verwendet wird.
Trotz vieler Vorteile, die der systematische Einsatz von Metriken mit sich bringt, werden sie in der Praxis noch kaum erhoben, was man nicht zuletzt darauf zurückführen kann, dass zumeist noch sehr unausgereifte Entwicklungsprozesse verwendet werden, bei denen Messungen einfach nicht vorgesehen sind und daher der Nutzen auch nicht so klar ist.
Wie in Kapitel 5 gezeigt wurde, gibt es eine Vielzahl von Metriken, weshalb eine zielorientierte Vorgehensweise beim Messen besonders wichtig ist, um aus der Unmenge verfügbarer Metriken diejenigen auszuwählen, die dazu beitragen, die gesetzten Ziele zu erreichen. Darüber hinaus ist auch der Einsatz von Werkzeugen eine notwendige Voraussetzung, um Metriken effektiv in den Softwareentwicklungsprozess einbinden zu können.
| [Bert98] | Meyer, B.; The role of object-oriented metrics; In: IEEE Computer, Vol. 31, No. 11, November 1998, S. 123-125; Verfügbar im Internet: http://archive.eiffel.com/doc/manuals/technology/bmarticles/computer/metrics/page.html; Dezember 2002 |
| [Bett00] | Bettschart, T.; Integrales Informatik-Controlling mit Function Points, Diplomarbeit vom August 2000; Verfügbar im Internet: http://www.bbi-c.ch/pdf/Diplomarbeit_NDS_BI2.pdf; Dezember 2002 |
| [Chidamber94] | Chidamber, S.R., Kemerer, C.F.; A metrics suite for object oriented design; In: IEEE Transactions on Software-Engineering, Vol. 20, No. 6, Juni 1994, S. 476-493; Verfügbar im Internet: http://www.pitt.edu/~ckemerer/clnieee.pdf; Dezember 2002 |
| [Fähn02] | Fähnrich, K.P.; Software-Management, Vorlesung vom SS2002; Verfügbar im Internet: http://ais.informatik.uni-leipzig.de/studium/vorlesungen/vorlesungen_2002_ss.html; Dezember 2002 |
| [Fowler00] | Fowler, M.; Refactoring - Wie sie das Design vorhandener Software verbessern; Reading: Addison-Wesley; 2000; ISBN: 3827316308 |
| [Hind99] | Hindel, B.; Software-Metriken; Verfügbar im Internet: http://www.methodpark.de/f-l_swepwue_de.html; Dezember 2002 |
| [JStyle] | JStyle Code-Review-Tool; Home Page: http://www.mmsindia.com/jstyle.html; Dezember 2002 |
| [Lich02] | Lichter, H..; Software-Qualitätssicherung, Vorlesung vom SS2002; Verfügbar im Internet: http://www-lufgi3.informatik.rwth-aachen.de/LUFGI3/EDUCATION/SS02/VL_SQS/CELLS/index.html; Dezember 2002 |
| [Rech86] | Rechenberg, P.: Ein neues Maß für die softwaretechnische Komplexität von Programmen; In: Informatik Forschung und Entwicklung; 1986 |
| [Somm01] | Sommerville, I.: Software-Engineering; Reading: Addison-Wesley; 2001; ISBN: 3827370019 |
| [Wal01] | Wallmüller, E.: Software-Qualitätsmanagement in der Praxis; Reading: Hanser; 2001; ISBN: 3446213678 |